全民blog時代不靠譜
最近幾天思考了一些關於blog現狀的話題。今天上午在Google Reader上看到一篇文章,題目為《博客已死;博客长存》,文章結尾說“以往的静态博客确实将要逝去,但又将通过WordPress以实时的社会化媒体个人门户的姿态重生。博客已死;博客长存。”
我倒是覺得blog一直好好的,沒有死也沒有活。只是在前幾天很多人都認為的誇大了blog,使之成為了泡沫。而一旦泡沫破裂,人們變感覺過去別人吹出來的東西(也就是blog)死了。事實上,blog一直在那裡,不為堯存,不為紂亡。
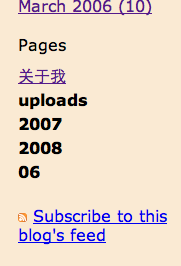 这是目前发现的最严重的一个问题。左边的截图就是我目前页面侧栏下方的截图,里面的关于我下面的uploads、2007、2008、06就是MT的上传程序给弄出来的。MT的上传图片窗口里,在Upload destination那一行的最右边有Choose folder链接,点击后就会出现下面的窗口:
这是目前发现的最严重的一个问题。左边的截图就是我目前页面侧栏下方的截图,里面的关于我下面的uploads、2007、2008、06就是MT的上传程序给弄出来的。MT的上传图片窗口里,在Upload destination那一行的最右边有Choose folder链接,点击后就会出现下面的窗口: 左边的这副“在互联网上,没人知道你是一条狗”漫画(详细描述请见
左边的这副“在互联网上,没人知道你是一条狗”漫画(详细描述请见