今天找到了一直想要的 Firefox 扩展
从昨晚开始,我正式把电脑的默认浏览器修改回了 Firefox。经过了前几日对 Vivaldi 的(无效)探索,我对标签页的管理略微产生了一点兴趣。于是今天搜索了一下 Firefox 的扩展,找一下跟标签页有关的,结果找到了这个——Tab Stash。
从昨晚开始,我正式把电脑的默认浏览器修改回了 Firefox。经过了前几日对 Vivaldi 的(无效)探索,我对标签页的管理略微产生了一点兴趣。于是今天搜索了一下 Firefox 的扩展,找一下跟标签页有关的,结果找到了这个——Tab Stash。
从上周一开始,我接到了一个任务,又是把系统里导出来的数据进行统计,输出结果。我用 Ruby 语言编写了一个简单的程序,来处理 Excel 导出的 CSV 文件。由于时间紧急,我没有仔细构思程序应该怎么设计,直接想到什么写什么,最终写出了程序,完成了任务。
最近,我开始重新学习 Perl,尝试用 Perl 来完成日常的开发程序。
原因是前几天听第 27 期内核恐慌时,主持人提到了 Perl 6。然后吴涛说起 Perl 时,感情很复杂。我当时心想,我对 Perl 的感情也很复杂咯。首先是对今天的程序员来说,Perl 太原始了,与 Python 和 Ruby 等语言相比,更显古老。回想起来,自从我学习了这两种语言后,我就再没有正儿八经用 Perl 写过程序。而我真正有了属于自己的电脑,是在 2007 年,那个时候我正好开始学习 Python,之后就没有碰过 Perl。
昨天要写一个简单的 Ruby 小程序,来快速的对一些数据做出统计。之前用的 Atom 来写的 Java 程序,缩紧方面的设置还需要重新调整。我觉得有些烦了,就干脆关了,用 Emacs 来写。
我的日常工作之一是统计非法走私信息,在国家级的行业信息系统上有一些数据,但不是我们要的格式。我们要把每个走私案件统计下来,包括走私的产品、数量、案值金额、还有涉及到哪个下属单位等信息。过去用眼镜跟手再加上 Excel 来整理实在是太麻烦了,于是我就写了一个 Ruby 程序,把导出的数据整理成我们需要的格式,输出成 HTML,大大减轻了工作量。
Emacs 是我最喜欢用的编辑器。最早我是在大约 2005 年从王垠的网站上知道它的,同时听说的还有 VIM,后来经过尝试,我觉得 Emacs 更加符合我的口味,用起来更为自然,因此从很早起我就用 Emacs 来写程序。
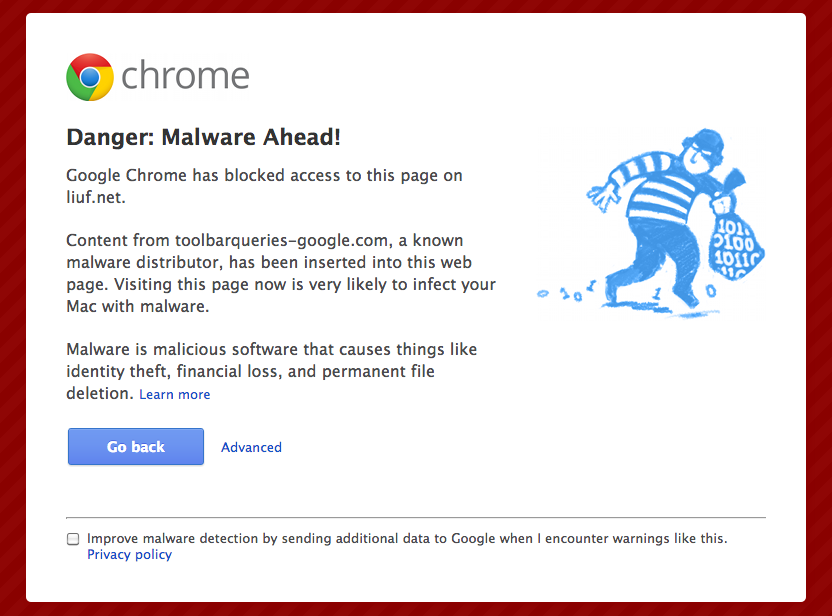
今天早上偶尔访问我的服务器上的文件时,发现当我访问一个 HTML 文件 时,Chrome 浏览器提醒我这个页面有不良程序。
前几天偶尔上 Twitter 的时候看到别人的一条推,说是 Twitter 可以导出自己过去发布的所有消息了。这是我一直想做的,原因之一是 Twitter 自己限制了它是一个快速更新的消息发布集中地,而已经发布了的消息就不是它所关注的了。所以过去你要是在 Twitter 页面上不断的点“上一页”,能看到的页面是有效的,印象里好像回退到 20 几页就不能再往前看了,不知道现在有没有改进。因此我很早之前就有把我所有的 Twitter 条目都导出来的想法,可惜 Twitter 的 API 也有类似的限制,因此这个想法一直没有实现。
我从 2009 年就想写一个程序,把我的 Twitter 记录生成为静态的网页,放在我的服务器上,可以让墙内的人浏览。这样,在国内的父母也可以像 Twitter 被封锁前那样通过我的 Twitter 来了解我的生活情况。
前几天一个偶然的机会我发现了 Shawn Blanc 的 blog。这个 blog 包含了一些时尚科技的评论,更新速度比较高。作者 Shawn Blanc 目前是专职维护这个 blog,blog 本身有收费会员订阅的项目,每月花 3 美元就可以阅读一些更多的内容。但免费的内容已经非常丰富了,作者有这个底气征收付款,在中文 blog 圈子中应该是比较难以想象的吧。