我喜欢剧透
人们对于剧透这件事情的认知有好有坏,不过我在现实环境中总觉得是反感剧透的居多。我在国内上大学的时候,有个室友就特别讨厌剧透,每次我们围在一起看电影的时候,一旦有人要剧透,他总会厉声制止。网上这种情况更多,我记得有一次看了一集Heroes,可能是那一集剧情特别跌宕起伏,我不禁在Twitter上赞叹了一句情节,结果立即有人回我“不要剧透”。老六曾经写过一篇文章,表达了他对剧透这一行为的愤慨,里面他讲的被剧透的事迹悲惨的可以用催人泪下来形容了。在维基百科上,很多关于影视作品的条目,在介绍剧情的片段时,常用技术把剧透的部分给隐藏起来,并提示下面内容可能会降低观赏性质云云,手动点击后才能看到。在美剧论坛里,在有剧透内容的帖子的标题上标明“剧透慎入”已经不是一种美德,而是一种基本的道德了。
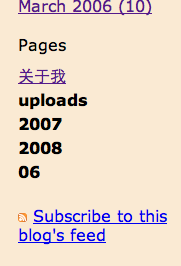 这是目前发现的最严重的一个问题。左边的截图就是我目前页面侧栏下方的截图,里面的关于我下面的uploads、2007、2008、06就是MT的上传程序给弄出来的。MT的上传图片窗口里,在Upload destination那一行的最右边有Choose folder链接,点击后就会出现下面的窗口:
这是目前发现的最严重的一个问题。左边的截图就是我目前页面侧栏下方的截图,里面的关于我下面的uploads、2007、2008、06就是MT的上传程序给弄出来的。MT的上传图片窗口里,在Upload destination那一行的最右边有Choose folder链接,点击后就会出现下面的窗口: