和菜头说的太对了!
今天(2023 年 6 月 28 日)晚上看到这篇和菜头的文章《重开博客》,实话说还是挺吃惊的。确切的说是看到和菜头的博客竟然还在,让我很吃惊。我原本以为像他那一批人,已经过了写博客的阶段了,比如李笑来、罗永浩、洪波他们。
今天(2023 年 6 月 28 日)晚上看到这篇和菜头的文章《重开博客》,实话说还是挺吃惊的。确切的说是看到和菜头的博客竟然还在,让我很吃惊。我原本以为像他那一批人,已经过了写博客的阶段了,比如李笑来、罗永浩、洪波他们。
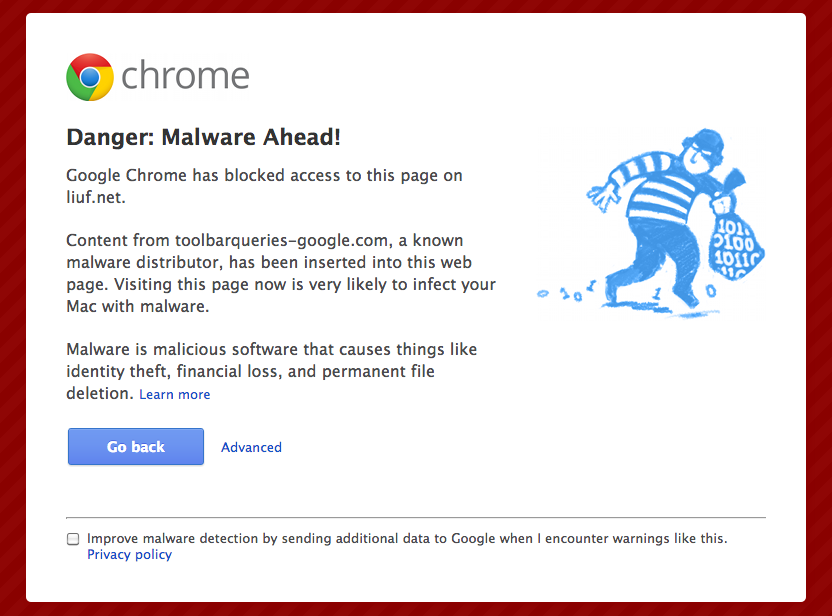
今天早上偶尔访问我的服务器上的文件时,发现当我访问一个 HTML 文件 时,Chrome 浏览器提醒我这个页面有不良程序。
好像在 2007 年初那会我对 blog 刚刚开始感兴趣的时候,就听说过 Blosxom 了。它是个非常简洁的 blog 发布软件。其核心程序只有一个 cgi 文件,里面是 Perl 代码。它的功能也十分简陋,连最基本的评论功能都没有。而这些功能都使通过插件来完成的,页面的样式通过 flavours 来安装。我曾经在自己的共享空间里实验过,比较麻烦,不符合我的要求,于是我就没有再管它。
今天我终于把自己的 wiki 系统换成了 MoinMoin。
我对 MoinMoin 算是觊觎已久了,我的 blog 上关于 MoinMoin 最早的一篇文章是两年前的《还是建了一个 wiki》,那也是我在自己的网站上搭建 wiki 的开始。本来我用 wiki 是像用它来管理我的网页,因为这样可以在浏览器里用方便的结构化文本来生成页面,而不用我麻烦的手写 HTML,当时我试用了几个 wiki 程序都不符合我的要求。主要原因是 wiki 的内容限制有些死板,我不想把我的首页弄得像一个 wiki,我想让它像一个网页。而那些 wiki 程序都以安全为由把用户可以输入的内容限制的死死的,令我非常不爽。后来我放弃了用 wiki 来管理整个网站的想法,转而建立一个单独的 wiki,于是我在当时用的 Site5 共享空间上用 MediaWiki 搭建了一个 wiki。当时我已经想用 MoinMoin 了,可惜用共享空间来搭建 MoinMoin 太麻烦,我最后放弃了。
随着对计算机的使用时间越来越长,我对于信息的种种理解也在不断变化着。
开始的时候我受版权的思想很深刻,也把一切都想象的很美好,坚定的认为所有信息都应该有且仅有一份,我们的网络通过超链接把所有的信息给串联起来,我们可以在任何地方、任何时间找到我们想要的任何信息。在这种思想的影响下,我认为一切“转载”之类的活动都是邪恶的,这种冗余浪费资源,也浪费我们搜索信息的效率,因此发生了这篇文章中记录的事。后来我不再那么激进了,但我依然不认为网上有了重复的内容是一件好事。管不了别人,我自己都是尽量按照这种要求来做的。
前天早上出门前的一段时间,我偶然间打开了著名的科技 blog TechCrunch。这个 blog 我很早之前就听说了,但我从来没有直接的阅读它。因为它的信息量非常大,而它的主题——一些新兴的计算机科技不是我特别关心的,因此我从来不订阅上面的文章,而是转而关注一些信息量稍微小一些的技术 blog。
前几个星期,我因为 Firefox 把我的系统拖的非常迟钝,我忍无可忍,于是把浏览器切换成了 Safari。
我在用 Firefox 打开一些标签页后,从 Activity Monitor 里 Firefox 占用的内存,基本上没有下来过 500M 的,经常还可以上 G。我的机器的内存一共才 2G,一个浏览器就给我占用一大半,这让我情何以堪啊。
在整个做网页的技术中,我唯一不在行的就是 CSS 了。严格来讲其它技术也不怎么在行,而我对于 CSS 则有种“畏惧”的心理,很长时间不敢动它。过去我同样有这种感觉的是 javascript,后来在今年暑假的学期中有一门课需要我们自己写 javascript 来做 AJAX 页面,那一阵子 firebug 和 Safari 的内建调试工具同时出动,虽然痛苦,也让我对 javascript 不那么恐惧了。而 CSS 则不然,我从头到尾一直都没有学过,因此虽然 CSS 不是一门很难的技术,我却一直感到恐惧。
这篇文章是我之前的一篇文章《Web 2.0和熵》的延续和补充。
在那篇文章里,我说混乱是互联网的趋势,因为世界趋于混乱,人心也趋于混乱,混乱符合大众的要求,因此帮助人们制造混乱的工具会火。于是Facebook火了、Twitter火了,不止如此,他们的一众模仿者也都或多或少的火了。然而今天我突然意识到,这个观点只描述了事实的一半。世界趋于混乱是真的,但我们还是需要秩序的,只有两者在维持一定平衡的状态下,世界运转才正常。不止网络如此,这应该是普适的真理。