三周里总结的Movable Type的问题
上次换网站的虚拟空间后,发现不知道中间少弄了哪一步,当时blog的1024px模板的侧栏不见了,去了页面下方,就像没有了css的效果。那个模板虽然不是我自己写的,但我当年也做了不少格式上的微调。我没写过PHP,因此对模板的改动也是现学现用,用了就忘,两年后早就忘了当时改了什么了。于是我那时就把blog程序换成了MT,主要想再学习理解一下另一个相当著名的blog程序。转眼三周已过,我在中间也写了不少文章,也发现了MT的一些缺点,总结如下。
1 上传程序会“创立页面”
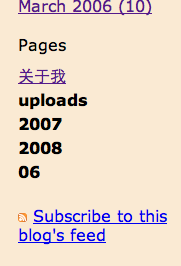 这是目前发现的最严重的一个问题。左边的截图就是我目前页面侧栏下方的截图,里面的关于我下面的uploads、2007、2008、06就是MT的上传程序给弄出来的。MT的上传图片窗口里,在Upload destination那一行的最右边有Choose folder链接,点击后就会出现下面的窗口:
这是目前发现的最严重的一个问题。左边的截图就是我目前页面侧栏下方的截图,里面的关于我下面的uploads、2007、2008、06就是MT的上传程序给弄出来的。MT的上传图片窗口里,在Upload destination那一行的最右边有Choose folder链接,点击后就会出现下面的窗口: